Modern Data Warehousing
28 Sep 2021
Modern Data Warehouse
- Used as the source for analysis, reporting, and online analytical processing (OLAP).
- Data warehouses have to handle “Big Data”.
- Big data is the term used for large quantities of data collected in escalating volumes, at higher velocities, and in a greater variety of formats.
- Historical (meaning stored) or real time (meaning streamed from the source).
- Modern data warehouse might contain a mixture of relational and non-relational data, including files, social media streams, and Internet of Things (IoT) sensor data.
- Data warehousing solution -> Azure Data Factory, Azure Data Lake Storage, Azure Databricks, Azure Synapse Analytics, and Azure Analysis Services.
- Power BI -> analyze and visualize the data, generating reports, charts, and dashboards.
- Combination of up-to-the-second data, and historical information.
Explore Azure data services for modern data warehousing
Azure Data Factory
- A data integration service.
- Purpose : retrieve data from one or more data sources, and convert it into a format that you process.
- Enables you to extract the interesting data, and discard the rest.
- Azure Data Factory as a pipeline of operations.
- A pipeline can run continuously, as data is received from the various data sources.
Azure Data Lake Storage
- A repository for large quantities of raw data.
- Data lake as a staging point for your ingested data, before it’s massaged and converted into a format suitable for performing analytics.
- A data warehouse also stores large quantities of data, but the data in a warehouse has been processed to convert it into a format for efficient analysis.
- A data lake holds raw data, but a data warehouse holds structured information.
- Azure Data Lake Storage is essentially an extension of Azure Blob storage, organized as a near-infinite file system.
- Charateristics of Data Lake Storage:
- Organizes your files into directories and subdirectories for improved file organization.
- Supports the Portable Operating System Interface (POSIX) file and directory permissions to enable granular Role-Based Access Control (RBAC) on your data.
- Compatible with the Hadoop Distributed File System (HDFS).
Azure Databricks
- Azure Databricks is an Apache Spark environment running on Azure to provide big data processing, streaming, and machine leark consumes large amounts of dataning.
- Apache Spark efficient data processing engine that can consume and process large amounts of data very quickly.
- Spark supports ->R,Python,Scala
- Spark code using notebooks . notebooks contains cells, each contains a seperate block of code.
Azure Synapse Analytics
- An analytics engine
- Azure Synapse Analytics leverages a massively parallel processing (MPP) architecture.
- The Control node is the brain of the architecture.
- The Compute nodes provide the computational power.
- Azure Synapse Analytics supports two computational models: SQL pools and Spark pools.
- In a SQL pool, each compute node uses an Azure SQL Database and Azure Storage to handle a portion of the data.
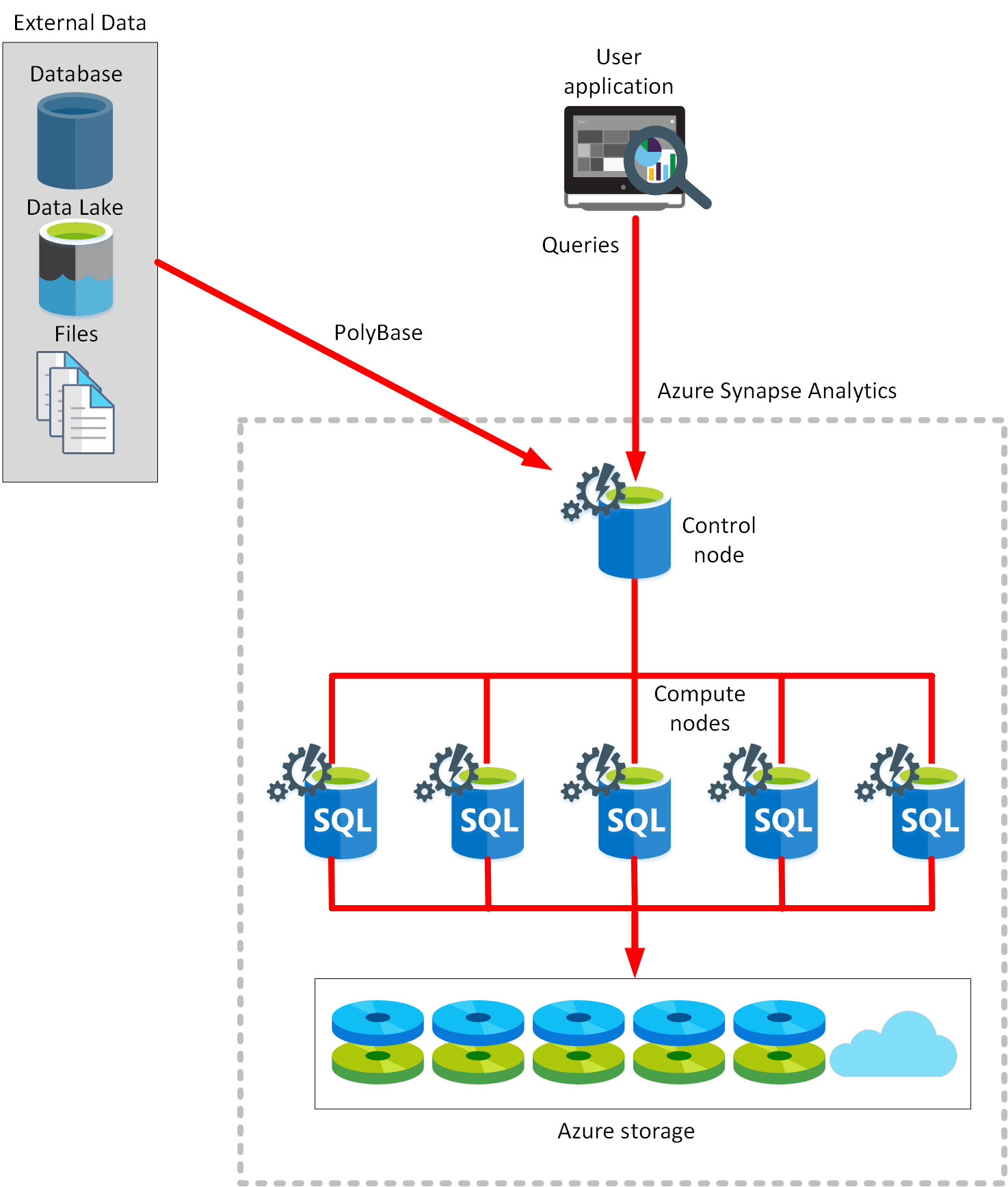
- submit queries -> Transact-SQL statements -> Azure Synapse Analytics runs them
- PolyBase enables you to retrieve data from relational and non-relational sources, such as delimited text files, Azure Blob Storage, and Azure Data Lake Storage.
- You can only scale a SQL pool when it’s not running a Transact-SQL query.
- Spark pool, the nodes are replaced with a Spark cluster
- Spark is optimized for in-memory processing. A Spark job can load and cache data into memory and query it repeatedly. In-memory computing is much faster than disk-based applications, but requires additional memory resources.
- Autoscaling can occur while processing is active.
Azure Analysis Services
- Build tabular models to support online analytical processing (OLAP) queries.
Use Azure Synapse Analytics for:
- Very high volumes of data (multi-terabyte to petabyte sized datasets).
- Very complex queries and aggregations.
- Data mining, and data exploration.
- Complex ETL operations.
- Low to mid concurrency (128 users or fewer).
Use Azure Analysis Services for:
- Smaller volumes of data (a few terabytes).
- Multiple sources that can be correlated.
- High read concurrency (thousands of users).
- Detailed analysis, and drilling into data, using functions in Power BI.
- Rapid dashboard development from tabular data.
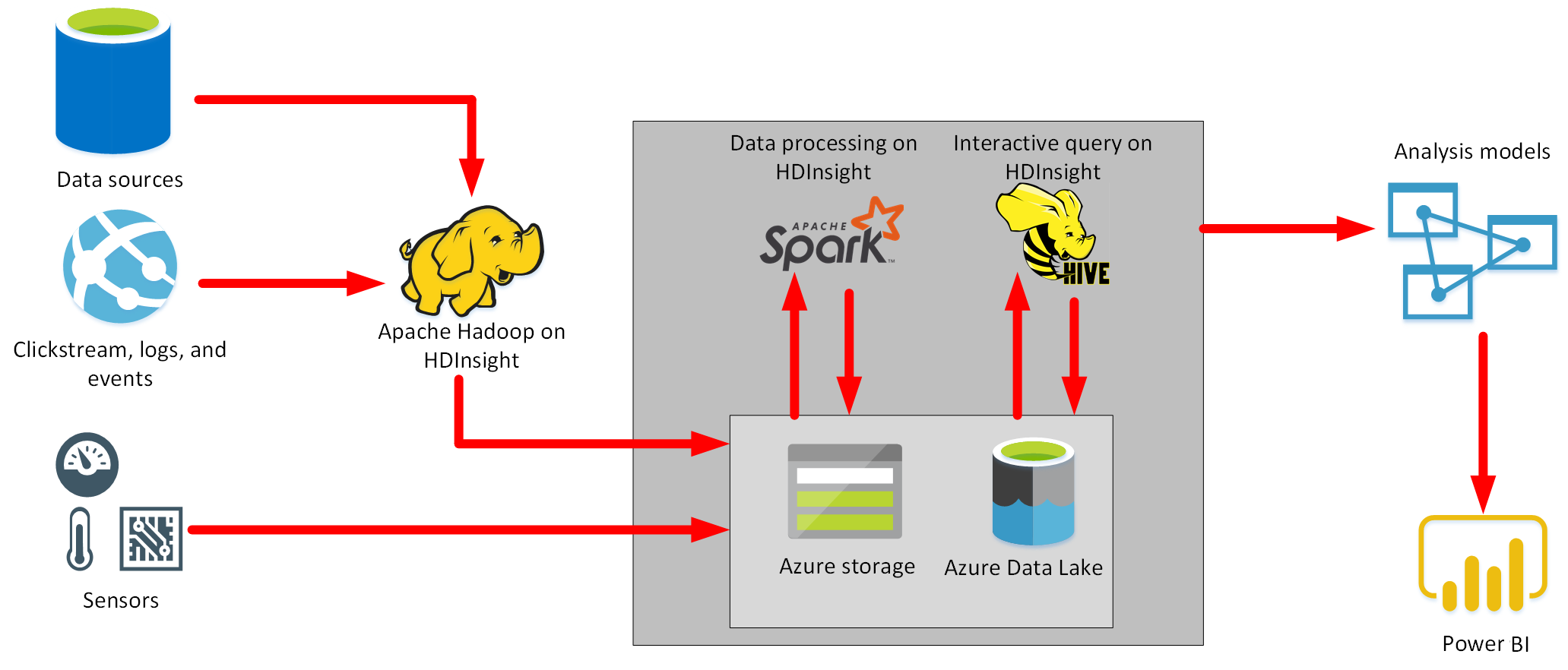
Azure HDInsight
- Azure HDInsight is a big data processing service.
- HDInsight implements a clustered model that distributes processing across a set of computers.
- This model is similar to that used by Synapse Analytics, except that the nodes are running the Spark processing engine rather than Azure SQL Database.
- Hadoop is an open source framework that breaks large data processing problems down into smaller chunks and distributes them across a cluster of servers, similar to the way in which Synapse Analytics operates.
- Hive is a SQL-like query facility that you can use with an HDInsight cluster to examine data held in a variety of formats. You can use it to create, load, and query external tables, in a manner similar to PolyBase for Azure Synapse Analytics
<- Back to Main Menu