Explore Core Data Concepts
22 Sep 2021Topics
- Identify how data is defined and stored
- Identify types of data and data storage
- Describe and differentiate batch and streaming data
Identify how data is defined and stored
What is data?
Data is a collection of facts such as numbers, descriptions, and observations used in decision making.
Classification of data :
- Structured,
- Semi-structured, or
- Unstructured.
Structured data
- Tabular data that is represented by rows and columns in a database.
- Databases that hold tables in this form are called relational databases (the mathematical term relation refers to an organized set of data held as a table).
Note: Each row in a table has the same set of columns.
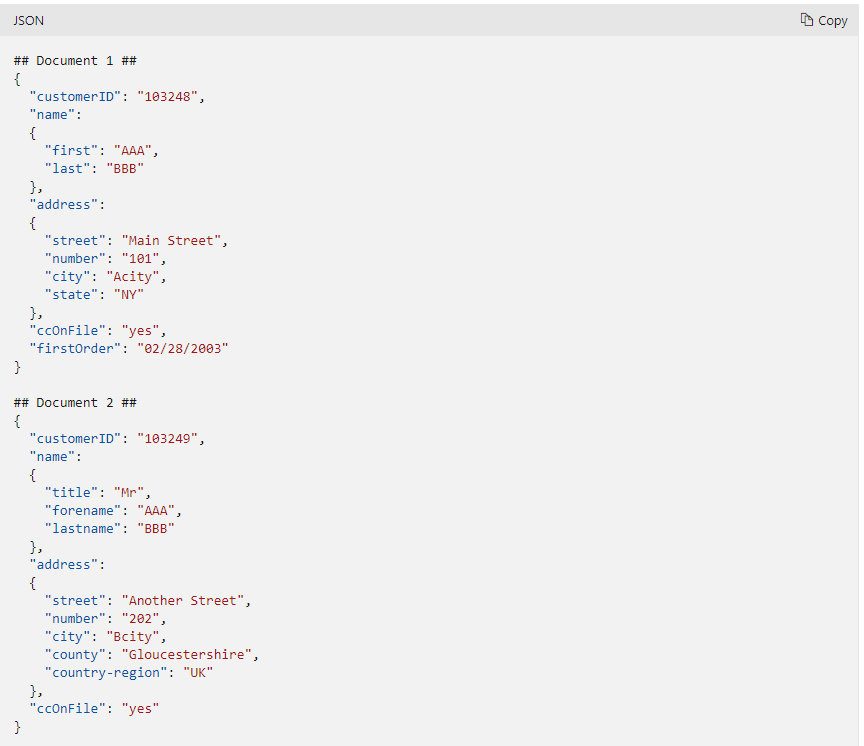
Semi-structured data
JSON
- It is information that doesn’t reside in a relational database but still has some structure to it.
Example: JavaScript Object Notation (JSON)
Key-Value Pair:
- A key-value database stores Associative arrays.
- A key-value database stores data as a single collection without structure or relation.
Unstructured data
Graph Database
- A graph contains nodes (information about objects), and edges (information about the relationships between objects).
Data defined, stored, and accessed in cloud computing
- Structured Data -> Relational Database such as SQL server or Azure SQL Database
- Unstructured Data ->Azure Blob Storage (Blob - Binary Large Object)
- Semi-strucutred Data->Azure CosmosDB
Levels of Access
- Read-Only
- Read/Write
- Owner - Full Privilege
Scenario
- Data Analyst/Data Engineer ->Owner
- Sales people -> Read-Only
Data Processing Solutions
Transactional System (OLTP - Online Transactional Processing)
- It records Transactions ( small,discrete unit of work)
- Splitting tables out into separate groups of columns like this is called normalization
- Advantage: Normalization can enable a transactional system to cache much of the information required to perform transactions in memory, and speed throughput.
- Disadvantage: normalized tables will frequently need to join the data held across several tables back together again. This can make it difficult for business users(Analysis) who might need to examine the data.
Analytical System
- Capturing raw data, and using it to generate insights for decision-making.
Tasks:
Data ingestion: the process of capturing the raw data. The repository could be a file store, a document database, or even a relational database.
Data transformation: Filter out anomolies, required tranformation like date or address etc., perform aggregation like,sum and other KPIs(Key Performance Indicators)
Data querying: Query to analyse the data.
Data visualization: - Visualizing the data can often be useful as a tool for examining data.
- Charts such as bar charts, line charts, plot results on geographical maps, pie charts, or illustrate how data changes over time.
- Microsoft Power BI - rich graphical representation of data.
Identify types of data and data storage
The characteristics of relational and non-relational data
Describe the characteristics of relational and non-relational data
Relational Database
- Simple table structure with Rows and Columns.
- Normalization: Data is split into a large number of narrow, well-defined tables (a narrow table is a table with few columns), with references from one table to another.
Non-Relational database
- Store data in a format that more closely matches the original structure.
- Example : Document DB
- Advantage: Ease of retrieving information ex: from one document.
- Disadvantage: 1. Duplication (Ex: Same address of two different people stored seperately) 2. Increase in storage and complex maintanance.
Describe transactional workloads
Relational Database workload
- Handles transaction processing.
- ACID (Atomicity, Consistency, Isolation and Durability)
- Atomicity: guarantees that each transaction is treated as a single unit, which either succeeds completely, or fails completely(power failures, errors, and crashes).
- Consistency: should never lose or create data in a manner that can’t be accounted for.
- Isolation: Ensures that concurrent execution of transactions leaves the database in the same state that would have been obtained if the transactions were executed sequentially.
- Durability: Guarantees that once a transaction has been committed, it will remain committed even if there’s a system failure such as a power outage or crash.
- Locks: 1.Implement relational consistency and isolation by applying locks to data when it is updated.
2. The lock is only released when the transaction commits or rolls back.
3. Disadvantage: Extensive locking can lead to poor performance, while applications wait for locks to be released.
Distributed Databases:
- A distributed database is a database in which data is stored across different physical locations.
- It may be held in multiple computers located in the same physical location (for example, a datacenter), or may be dispersed over a network of interconnected computers.
- Takes more time to update.
- locks may be retained for a very long time, especially if there’s a network failure between databases at a critical point in time. To counter this problem, many distributed database management systems relax the strict isolation requirements of transactions and implement “eventual consistency.”
- Eventual consistency: 1. Definition - as an application writes data, each change is recorded by one server and then propagated to the other servers in the distributed database system asynchronously. 2. Adv - helps to minimize latency, it can lead to temporary inconsistencies in the data. 3. Used - the application doesn’t require any ordering guarantees. Examples include counts of shares, likes, or non-threaded comments in a social media system.
Describe analytical workloads
- Read-only systems that store vast volumes of historical data or business metrics, such as sales performance and inventory levels.
- Data analysis and decision making.
- Generated by aggregating the facts presented by the raw data into summaries, trends, and other kinds of “Business information.”
- Snapshot of the data at a given point in time, or a series of snapshots(provides bigger picture).
- Example : Monthly Reports
Describe the difference between batch and streaming data
- Data processing : the conversion of raw data to meaningful information through a process.
- Types od Data ingestion:
- Processing data as it arrives is called streaming.
- Buffering and processing the data in groups is called batch processing.
Understand batch processing
- Newly arriving data elements are collected into a group.
- The whole group is then processed at a future time as a batch.
- Ways of group processing:
- scheduled time interval (for example, every hour)
- it could be triggered when a certain amount of data has arrived, or as the result of some other event.
- Advantages of batch processing include:
- Large volumes of data can be processed at a convenient time.
- Scheduled to run at a time when computers or systems might be idle, such as overnight, or during off-peak hours.
- Disadvantages of batch processing include:
- The time delay between ingesting the data and getting the results.
- All of a batch job’s input data must be ready before a batch can be processed (carefully checked,Problems with data, errors, and program crashes that occur during batch jobs bring the whole process to a halt, the input data must be carefully checked before the job can be run again, typographical errors in dates)
Understand streaming and real-time data
- Each new piece of data is processed when it arrives.
- Streaming handles data in real time.
- No waiting until the next batch processing interval
- Most scenarios where new, dynamic data is generated on a continual basis.
- Example : financial institution(stock markert) , online gaming, real-estate website
Understand differences between batch and streaming data
| Differences | Batch | Streaming |
|---|---|---|
| Data Scope | process all the data in the dataset | most recent data received, or within a rolling time window (the last 30 seconds, for example) |
| Data Size | handling large datasets efficiently | individual records or micro batches consisting of few records |
| Performance | few hours latency | order of seconds or milliseconds |
| Analysis | performing complex analytics | simple response functions, aggregates, or calculations such as rolling averages |