Concepts of data analytics
27 Sep 2021Data analytics
- Taking data and finding meaningful information and inferences from it.
- Helps to identify strengths and weaknesses of organization to enable with business decisions.
- Data warehouse requires that you can capture the data that you need and wrangle it into an appropriate format.
- Wrangling is the process by which you transform and map raw data into a more useful format for analysis. It can involve writing code to capture, filter, clean, combine, and aggregate data from many sources.
- Two important stages in data analytics: 1) data ingestion 2) data processing
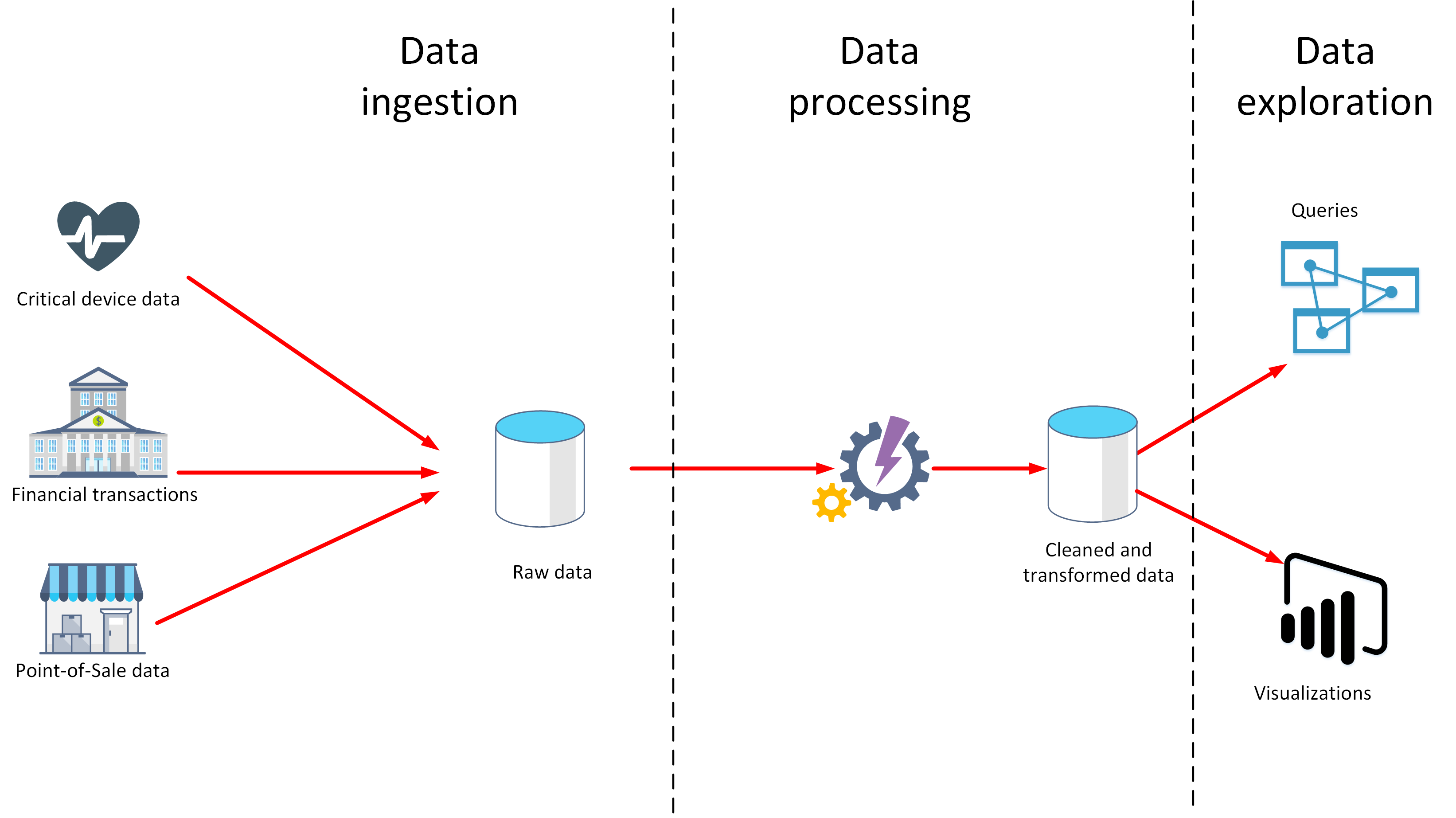
Data ingestion
- Process of obtaining and importing data for immediate use or storage in a database.
- The data can arrive as a continuous stream, or it may come in batches, depending on the source.
- The purpose of the ingestion process is to capture this data and store it.
- This raw data can be held in a repository such as a database management system, a set of files, or some other type of fast, easily accessible storage.
- Ingestion process might also perform filtering(reject suspicious, corrupt, or duplicated data).
- Perform some transformations at this stage, converting data into a standard form for later processing(reformat all date and time data to use the same date and time representations, and convert all measurement data to use the same units.).
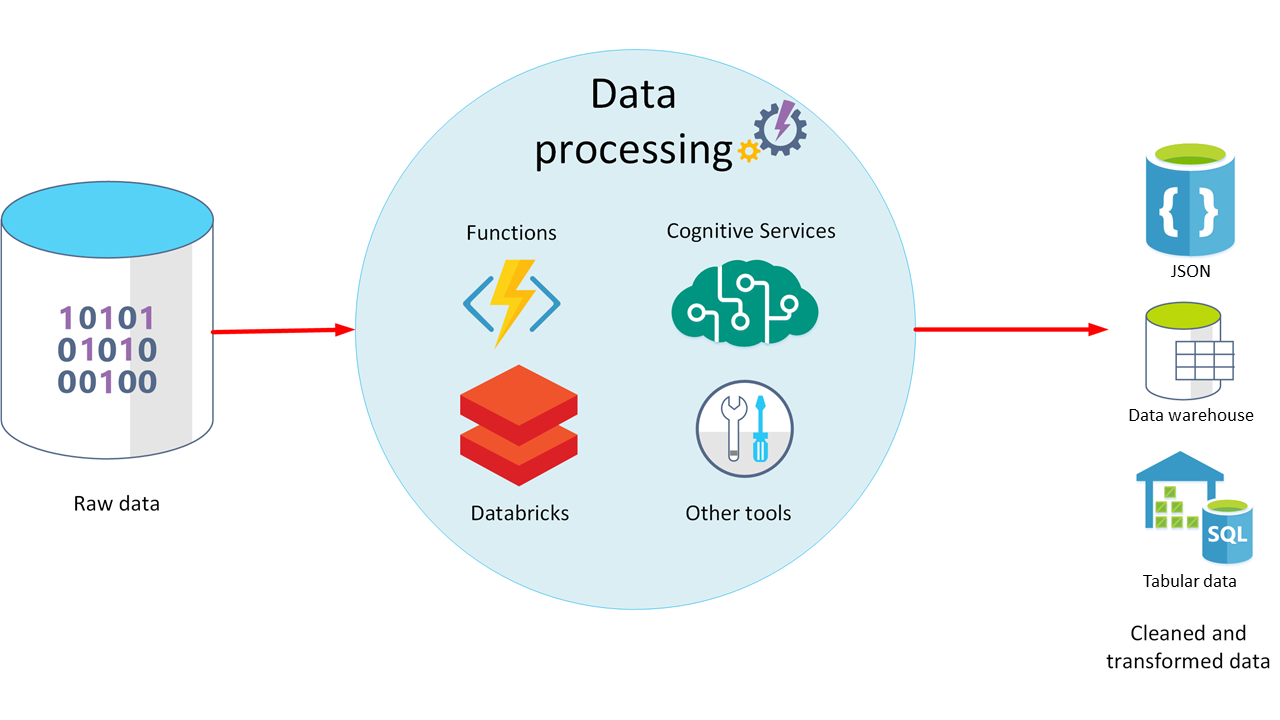
Data Processing
- The data processing stage occurs after the data has been ingested and collected.
- Data processing takes the data in its raw form, cleans it, and converts it into a more meaningful format (tables, graphs, documents, and so on).
Data cleaning
- A generalized term that encompasses a range of actions, such as removing anomalies, and applying filters and transformations that would be too time-consuming to run during the ingestion stage.
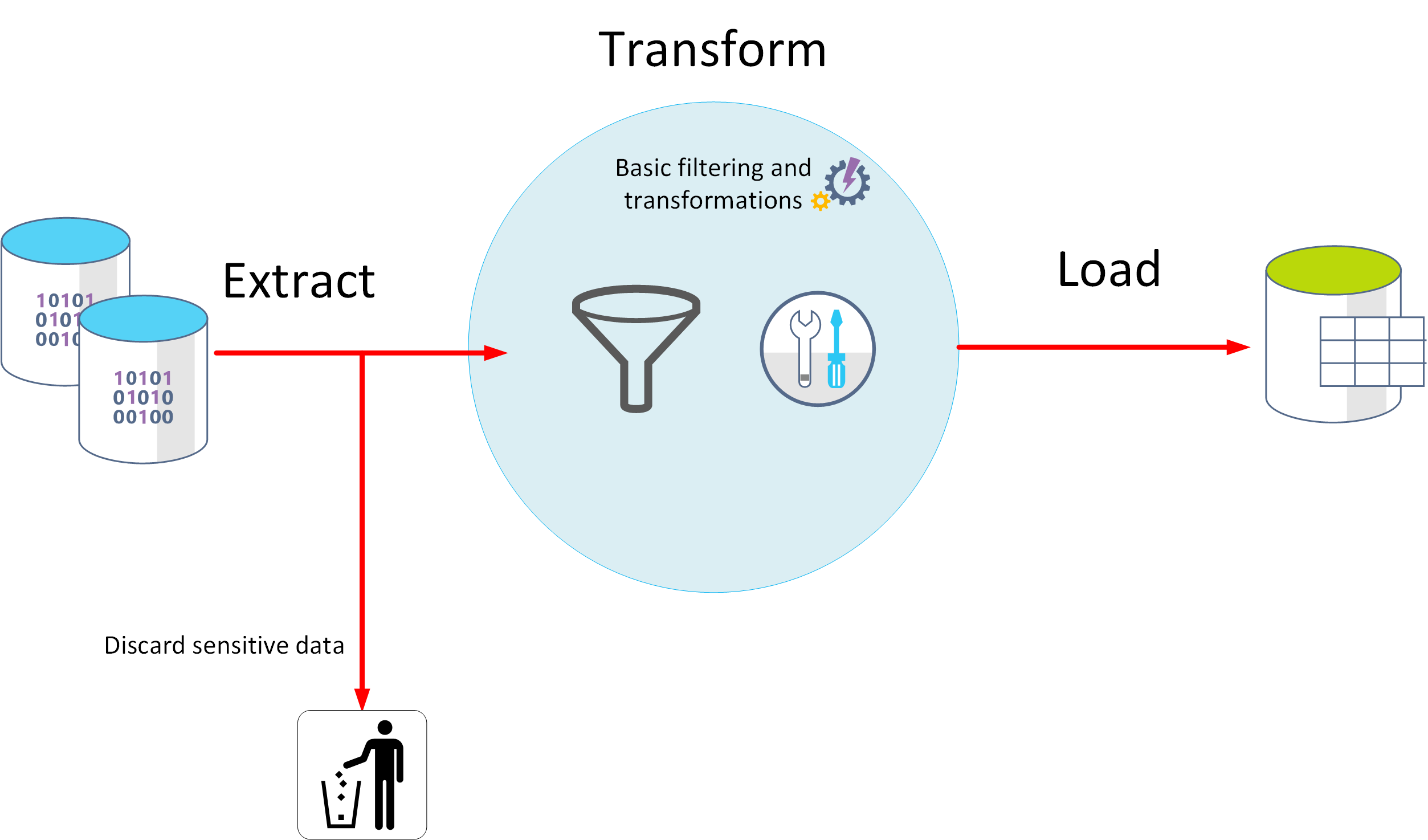
ETL
- ETL stands for Extract, Transform, and Load.
- The raw data is retrieved and transformed before being saved.
- continuous pipeline of operations.
- Basic data cleaning tasks, deduplicating data, and reformatting the contents of individual fields.
ELT
- Extract, Load, and Transform
- The data processing engine can take an iterative approach, retrieving and processing the data from storage, before writing the transformed data and models back to storage.
- ELT is more suitable for constructing complex models that depend on multiple items in the database, often using periodic batch processing.
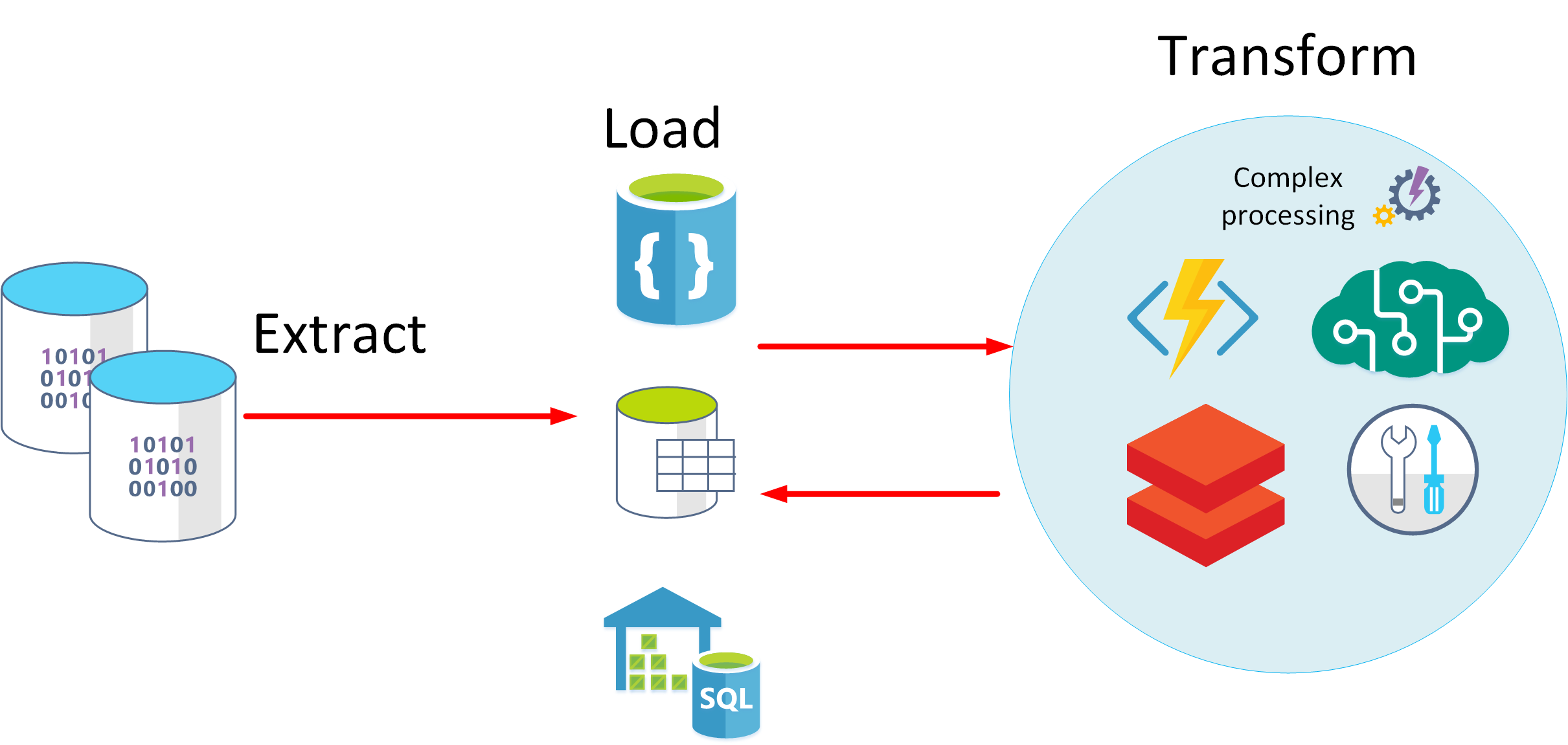
- scalable ->suitable for cloud.
- Stream oriented ->ETL

Azure Data Factory,
Create and schedule data-driven workflows (called pipelines) that can ingest data from disparate data stores. You can build complex ETL processes that transform data visually with data flows, or by using compute services such as Azure HDInsight Hadoop, Azure Databricks, and Azure SQL Database.