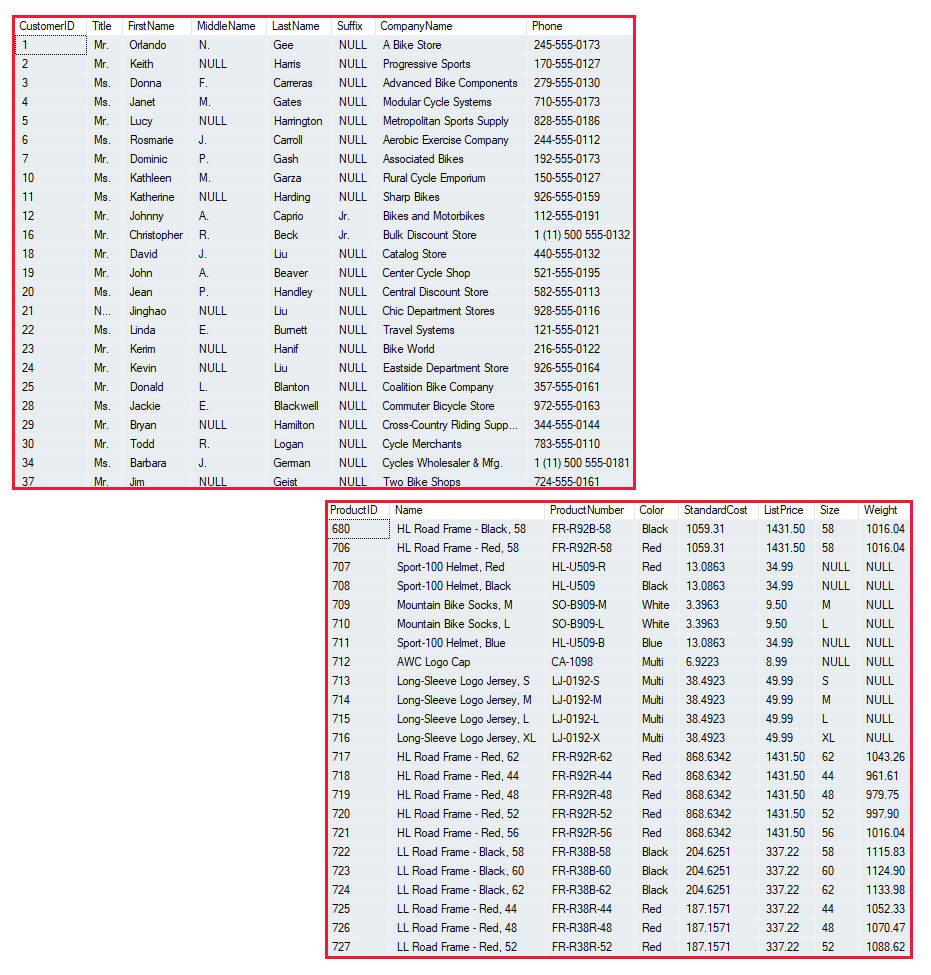
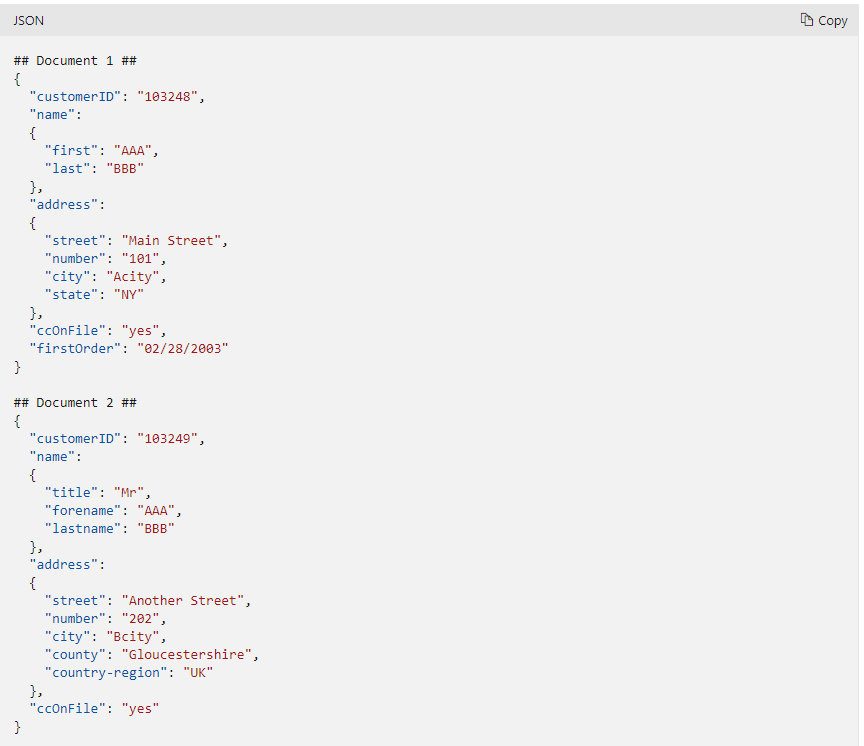
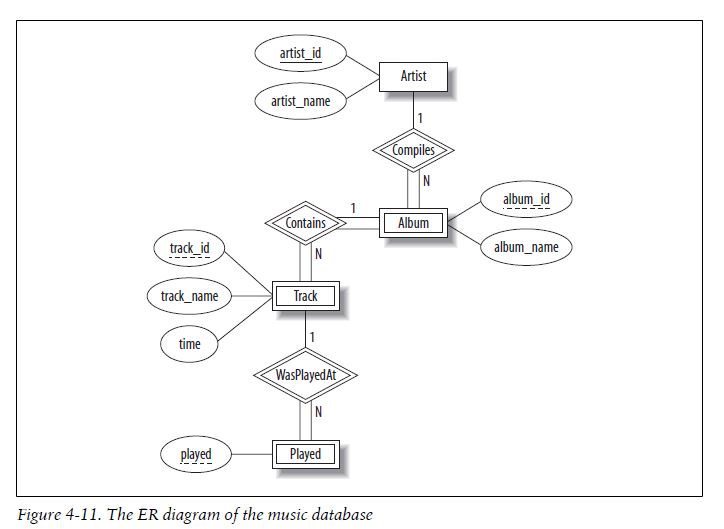
[(0, 'Elegia', 1, 1, Decimal('4.93')), (1, 'In A Lonely Place', 1, 1, Decimal('6.26')), (2, 'Procession', 1, 1, Decimal('4.47')), (3, 'Your Silent Face', 1, 1, Decimal('5.99')), (4, 'Sunrise', 1, 1, Decimal('6.01')), (5, "Let's Go", 1, 1, Decimal('3.90')), (6, 'Broken Promise', 1, 1, Decimal('3.76')), (7, 'Dreams Never End', 1, 1, Decimal('3.20')), (8, 'Cries And Whispers', 1, 1, Decimal('3.42')), (9, 'All Day Long', 1, 1, Decimal('5.18')), (10, 'Sooner Than You Think', 1, 1, Decimal('5.21')), (11, 'Leave Me Alone', 1, 1, Decimal('4.67')), (12, 'Lonesome Tonight', 1, 1, Decimal('5.19')), (13, 'Every Little Counts', 1, 1, Decimal('4.47')), (14, 'Run Wild', 1, 1, Decimal('3.95')), (0, 'In A Lonely Place', 1, 2, Decimal('6.30')), (1, 'Procession', 1, 2, Decimal('4.46')), (2, 'Mesh', 1, 2, Decimal('3.44')), (3, 'Hurt', 1, 2, Decimal('6.98')), (4, 'The Beach', 1, 2, Decimal('7.32')), (5, 'Confusion', 1, 2, Decimal('7.64')), (6, 'Lonesome Tonight', 1, 2, Decimal('5.20')), (7, 'Murder', 1, 2, Decimal('3.93')), (8, 'Thieves Like Us', 1, 2, Decimal('6.95')), (9, 'Kiss Of Death', 1, 2, Decimal('7.05')), (10, 'Shame Of The Nation', 1, 2, Decimal('7.91')), (11, '1963', 1, 2, Decimal('5.63')), (0, 'Fine Time', 1, 3, Decimal('4.71')), (1, 'Temptation', 1, 3, Decimal('8.71')), (2, 'True Faith', 1, 3, Decimal('5.88')), (3, 'The Perfect Kiss', 1, 3, Decimal('4.83')), (4, 'Ceremony', 1, 3, Decimal('4.41')), (5, 'Regret', 1, 3, Decimal('4.14')), (6, 'Crystal', 1, 3, Decimal('6.83')), (7, 'Bizarre Love Triangle', 1, 3, Decimal('4.35')), (8, 'Confusion', 1, 3, Decimal('8.22')), (9, 'Round And Round', 1, 3, Decimal('4.52')), (10, 'Blue Monday', 1, 3, Decimal('7.48')), (11, 'Brutal', 1, 3, Decimal('4.83')), (12, 'Slow Jam', 1, 3, Decimal('4.88')), (13, 'Everyone Everywhere', 1, 3, Decimal('4.43')), (0, '"Ceremony [Studio 54, Barcelona 7/7/84]"', 1, 4, Decimal('4.82')), (1, '"Procession [Polytechnic of Central London, London 6/12/85]"', 1, 4, Decimal('3.57')), (2, '"Everything\'s Gone Green [Tolworth Recreation Centre, London 12/3/85]"', 1, 4, Decimal('5.25')), (3, 'In A Lonely Place [Glastonbury Festival 20/6/81]', 1, 4, Decimal('5.55')), (4, '"Age Of Consent [Spectrum Arena, Warrington 1/3/86]"', 1, 4, Decimal('5.04')), (5, 'Elegia [Glastonbury Festival 19/6/87]', 1, 4, Decimal('4.77')), (6, 'The Perfect Kiss [Glastonbury Festival 19/6/87]', 1, 4, Decimal('9.73')), (7, '"Fine Time [Popular Creek Music Theatre, Chicago 30/6/89]"', 1, 4, Decimal('5.04')), (8, '"World [Starplex Amphitheatre, Dallas 21/7/93]"', 1, 4, Decimal('4.81')), (9, 'Regret [Reading Festival 29/8/93]', 1, 4, Decimal('4.03')), (10, 'As It Is When It Was [Reading Festival 29/8/93]', 1, 4, Decimal('3.80')), (11, '"Intermission By Alan Wise [Olympia, Paris 12/11/01]"', 1, 4, Decimal('1.34')), (12, '"Crystal [Big Day Out, Gold Coast 20/1/02]"', 1, 4, Decimal('6.86')), (13, '"Turn My Way [Olympia, Liverpool 18/7/01]"', 1, 4, Decimal('4.96')), (14, '"Temptation [Big Day Out, Gold Coast 20/1/02]"', 1, 4, Decimal('7.79')), (0, 'Age Of Consent', 1, 5, Decimal('5.26')), (1, 'We All Stand', 1, 5, Decimal('5.24')), (2, 'The Village', 1, 5, Decimal('4.62')), (3, '5 8 6', 1, 5, Decimal('7.52')), (4, 'Your Silent Face', 1, 5, Decimal('6.00')), (5, 'Ultraviolence', 1, 5, Decimal('4.87')), (6, 'Ecstasy', 1, 5, Decimal('4.42')), (7, 'Leave Me Alone', 1, 5, Decimal('4.69')), (0, 'Ceremony', 1, 6, Decimal('4.42')), (1, "Everything's Gone Green", 1, 6, Decimal('5.51')), (2, 'Temptation', 1, 6, Decimal('6.99')), (3, 'Blue Monday', 1, 6, Decimal('7.49')), (4, 'Confusion', 1, 6, Decimal('4.72')), (5, 'Thieves Like Us', 1, 6, Decimal('6.61')), (6, 'Perfect Kiss', 1, 6, Decimal('8.04')), (7, 'Subculture', 1, 6, Decimal('4.80')), (8, 'Shellshock', 1, 6, Decimal('6.48')), (9, 'State of the Nation', 1, 6, Decimal('6.54')), (10, 'Bizarre Love Triangle', 1, 6, Decimal('6.74')), (11, 'True Faith', 1, 6, Decimal('5.93')), (0, 'State of the Nation', 1, 7, Decimal('6.56')), (1, 'Every Little Counts', 1, 7, Decimal('4.48')), (2, 'Angel Dust', 1, 7, Decimal('3.73')), (3, 'All Day Long', 1, 7, Decimal('5.21')), (4, 'Bizarre Love Triangle', 1, 7, Decimal('4.37')), (5, 'Way of Life', 1, 7, Decimal('4.11')), (6, 'Broken Promise', 1, 7, Decimal('3.80')), (7, 'As It Is When It Was', 1, 7, Decimal('3.77')), (8, 'Weirdo', 1, 7, Decimal('3.89')), (9, 'Paradise', 1, 7, Decimal('3.86')), (0, 'Do You Love Me?', 2, 1, Decimal('5.95')), (1, "Nobody's Baby Now", 2, 1, Decimal('3.87')), (2, 'Loverman', 2, 1, Decimal('6.37')), (3, 'Jangling Jack', 2, 1, Decimal('2.78')), (4, 'Red Right Hand', 2, 1, Decimal('6.18')), (5, 'I Let Love In', 2, 1, Decimal('4.25')), (6, 'Thirsty Dog', 2, 1, Decimal('3.81')), (7, "Ain't Gonna Rain Anymore", 2, 1, Decimal('3.77')), (8, 'Lay Me Low', 2, 1, Decimal('5.15')), (9, 'Do You Love Me? (Part Two)', 2, 1, Decimal('6.23')), (0, 'In A Silent Way', 3, 1, Decimal('1.81')), (1, 'Intruder', 3, 1, Decimal('4.87')), (2, 'New Blues', 3, 1, Decimal('5.58')), (3, 'Human Nature', 3, 1, Decimal('12.80')), (4, 'Mr. Pastorius', 3, 1, Decimal('3.54')), (5, 'Amandla', 3, 1, Decimal('5.87')), (6, 'Wrinkle', 3, 1, Decimal('7.28')), (7, 'Tutu', 3, 1, Decimal('8.89')), (8, 'Full Nelson', 3, 1, Decimal('2.81')), (9, 'Time After Time', 3, 1, Decimal('9.98')), (10, 'Hannibal', 3, 1, Decimal('7.37')), (0, 'Shhh/Peaceful', 3, 2, Decimal('16.67')), (1, "In A Silent Way/It's About That Time", 3, 2, Decimal('16.67')), (0, 'Rocks Off', 4, 1, Decimal('4.54')), (1, 'Rip This Joint', 4, 1, Decimal('2.38')), (2, 'Shake Your Hips', 4, 1, Decimal('3.00')), (3, 'Casino Boogie', 4, 1, Decimal('3.57')), (4, 'Tumbling Dice', 4, 1, Decimal('3.79')), (5, 'Sweet Virginia', 4, 1, Decimal('4.44')), (6, 'Torn & Frayed', 4, 1, Decimal('4.30')), (7, 'Sweet Black Angel', 4, 1, Decimal('2.97')), (8, 'Loving Cup', 4, 1, Decimal('4.43')), (9, 'Happy', 4, 1, Decimal('3.08')), (10, 'Turd On The Run', 4, 1, Decimal('2.64')), (11, 'Ventilator Blues', 4, 1, Decimal('3.40')), (12, 'I Just Want To See His Face', 4, 1, Decimal('2.90')), (13, 'Let It Loose', 4, 1, Decimal('5.31')), (14, 'All Down The Line', 4, 1, Decimal('3.84')), (15, 'Stop Breaking Down', 4, 1, Decimal('4.57')), (16, 'Shine A Light', 4, 1, Decimal('4.28')), (17, 'Soul Survivor', 4, 1, Decimal('3.82')), (0, 'Breaking Into Heaven', 5, 1, Decimal('11.37')), (1, 'Driving South', 5, 1, Decimal('5.17')), (2, 'Ten Storey Love Song', 5, 1, Decimal('4.50')), (3, 'Daybreak', 5, 1, Decimal('6.56')), (4, 'Your Star Will Shine', 5, 1, Decimal('2.99')), (5, 'Straight To The Man', 5, 1, Decimal('3.26')), (6, 'Begging You', 5, 1, Decimal('4.94')), (7, 'Tightrope', 5, 1, Decimal('4.45')), (8, 'Good Times', 5, 1, Decimal('5.67')), (9, 'Tears', 5, 1, Decimal('6.84')), (10, 'How Do You Sleep', 5, 1, Decimal('4.99')), (11, 'Love Spreads', 5, 1, Decimal('5.79')), (12, 'Untitled', 5, 1, Decimal('6.43')), (0, 'Spinning Around', 6, 1, Decimal('3.46')), (1, 'On A Night Like This', 6, 1, Decimal('3.55')), (2, 'So Now Goodbye', 6, 1, Decimal('3.62')), (3, 'Disco Down', 6, 1, Decimal('3.96')), (4, 'Loveboat', 6, 1, Decimal('4.18')), (5, 'Koocachoo', 6, 1, Decimal('4.00')), (6, 'Your Disco Needs You', 6, 1, Decimal('3.56')), (7, 'Please Stay', 6, 1, Decimal('4.14')), (8, 'Bittersweet Goodbye', 6, 1, Decimal('3.72')), (9, 'Butterfly', 6, 1, Decimal('4.16')), (10, 'Under The Influence Of Love', 6, 1, Decimal('3.40')), (11, "I'm So High", 6, 1, Decimal('3.55')), (12, 'Kids', 6, 1, Decimal('4.34'))]